Note
Go to the end to download the full example code
Assembling WBs#
An important part of the Mobilise-D pipeline is that we output WBs based on a fixed set of definitions. These definitions are build based on a consensus process within the Mobilise-D consortium [1] and additional normative data from the literature to define realistic ranges for stride and WB level parameters.
To support the process of creating WBs based on these and further custom rules, we provide a framework of dynamic rule objects that can be adjusted and combined and then used to create WBs from a list of strides. This works in 3 steps:
First, we filter the list of strides based on the stride-level rules.
Second, we iterate through the remaining list of strides and add them to a WB, until we reach a “Termination Criterion”.
The WBs found in this way are then finally filtered based on WB-level rules.
# TODO: Update the example with real stride values and rules
Step 1: Stride Selection#
Stride selection is a relatively simple process. Each stride is defined by its start and end time and a set of parameters. Stride-level rules are basically just threshold rules for these parameters or the duration of the stride.
Let’s start by creating a list of strides with dummy values. We specifically create list of “left” and “right” strides and combine them at the end.
from itertools import count
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
id_counter = count(1)
def window(start, end, **parameter):
parameter = parameter or {}
parameter = {**parameter, "duration": end - start}
return dict(s_id=next(id_counter), start=start, end=end, **parameter)
def naive_stride_list(start, stop, duration, foot=None, **paras):
"""A window list full of identical strides."""
x = np.arange(start, stop + duration, duration, dtype="int64")
start_end = zip(x[:-1], x[1:])
return pd.DataFrame.from_records(
[
window(start=s, end=e, foot=foot, duration=duration, **paras)
for s, e in start_end
]
).set_index("s_id")
stride_list = [
naive_stride_list(0, 5000, 100, foot="left"),
naive_stride_list(50, 5050, 100, foot="right"),
naive_stride_list(5000, 6020, 60, foot="left"),
naive_stride_list(5050, 6070, 60, foot="right"),
naive_stride_list(6020, 8000, 90, foot="left"),
naive_stride_list(6070, 8050, 90, foot="right"),
]
stride_list = pd.concat(stride_list).sort_values("start")
# We reset the stride ids to have them in ascending order.
stride_list = stride_list.reset_index(drop=True).rename_axis(index="s_id")
stride_list.index += 1
# We add some additional parameters, we can use to filter later on.
large_sl_ids = [10, 11, 12, 13, 14, 18, 19, 20, 21, 56, 90, 91, 121, 122, 176]
stride_list["stride_length"] = 1
stride_list.loc[stride_list.index[large_sl_ids], "stride_length"] = 2
stride_list
We can filter the stride list above based on a set of rules.
We start with some simple rules to demonstrate the process.
All rules must be subclasses of BaseIntervalCriteria.
At the moment we have implemented IntervalParameterCriteria and
IntervalDurationCriteria.
But you could implement custom subclasses, if you see a need for it.
Here we just implement a simple rule that filters strides based on their stride length for now. With the thresholds, all strides, we marked as “large” above should be filtered out.
from mobgap.wba import IntervalParameterCriteria
rules = [
(
"sl_thres",
IntervalParameterCriteria(
"stride_length", lower_threshold=0.5, upper_threshold=1.5
),
)
]
We can now use these rules to filter the stride list.
from mobgap.wba import StrideSelection
stride_selection = StrideSelection(rules)
stride_selection.filter(stride_list, sampling_rate_hz=1)
filtered_stride_list = stride_selection.filtered_stride_list_
filtered_stride_list
filtered_stride_list["stride_length"].unique()
array([1])
As we can see all the strides above the threshold were filtered out.
Let’s make this a little more complicated and add a second rule that filters strides based on their duration.
This could either be done by a second rule targeting the parameter duration or by using the
IntervalDurationCriteria, which recalculates the duration of the stride based on the
start and end columns.
We use the latter here.
The thresholds we use here should filter out all the strides from above with a duration of 60
from mobgap.wba import IntervalDurationCriteria
rules.append(
(
"dur_thres",
IntervalDurationCriteria(min_duration_s=80, max_duration_s=120),
)
)
stride_selection = StrideSelection(rules)
stride_selection.filter(stride_list, sampling_rate_hz=1)
filtered_stride_list = stride_selection.filtered_stride_list_
filtered_stride_list
filtered_stride_list["duration"].unique()
array([100, 90])
We can also explicitly inspect which strides are filtered out.
stride_selection.excluded_stride_list_
And even see which rule filtered them out. Note, that only the first rule that filtered the stride is shown.
stride_selection.excluded_stride_list_.merge(
stride_selection.exclusion_reasons_, left_index=True, right_index=True
)
Step 2,3: WB Assembly#
Now that we have a list of strides that we consider valid, we want to group them into WBs.
For this we define a set of rules that define when a WB should be terminated and if a preliminary WB fulfills
the criteria to be a valid WB.
These rules are subclasses of BaseWbCriteria and each rule can act as both a termination
criterion and an inclusion criterion.
Have a look at the documentation of the specific rules for more details.
For more details on how the rules are applied, have a look at the documentation of the
WbAssembly.
For this example, we use two rules:
MaxBreakCriteria: This rule terminates a WB if the time between two strides is larger than a given threshold. It acts as a termination criterion.NStridesCriteria: This rule excludes preliminary WBs that have less than a given number of strides. It acts as an inclusion criterion.
from mobgap.wba import MaxBreakCriteria, NStridesCriteria, WbAssembly
rules = [
(
"max_break",
MaxBreakCriteria(
max_break_s=10,
remove_last_ic="per_foot",
consider_end_as_break=True,
),
),
("min_strides", NStridesCriteria(min_strides=5)),
]
wb_assembly = WbAssembly(rules)
# Note, that we use the filtered stride list from above.
wb_assembly.assemble(filtered_stride_list, sampling_rate_hz=1)
WbAssembly(rules=[('max_break', MaxBreakCriteria(consider_end_as_break=True, max_break_s=10, remove_last_ic='per_foot')), ('min_strides', NStridesCriteria(min_strides=5, min_strides_left=None, min_strides_right=None))])
The wb_assembly object now contains a grouping of each stride to a WB.
Depending on how we want to further process the data, we can either use the wbs_ attribute, which is a dictionary
mapping a WB id to a list of strides, or the annotated_stride_list_ attribute, which is a copy of the stride list
containing an additional column wb_id that contains the id of the WB the stride belongs to.
Note, that both outputs only contain the strides that belong to a final WB.
Strides belonging to a WB that was ultimately filtered out, or never belonged to a WB in the first place are not
included.
They can be accessed via the excluded_stride_list_ and excluded_wbs attributes.
print(f"The method identified {len(wb_assembly.wbs_)} WBs.")
The method identified 4 WBs.
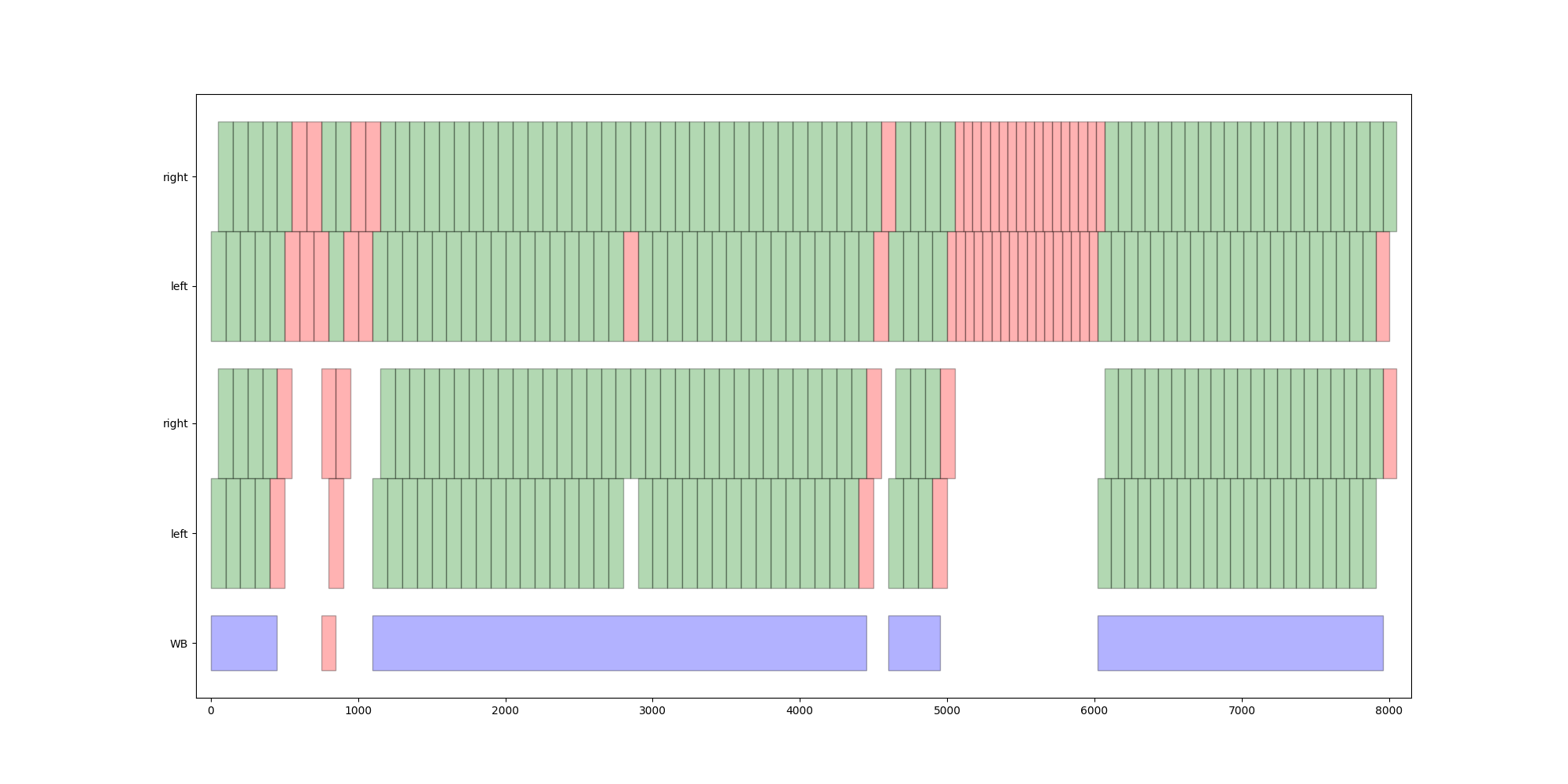
We can also get an idea of how the final results looks, by plotting the wba outputs.
from mobgap.wba.plot import plot_wba_results
plot_wba_results(wb_assembly, stride_selection=stride_selection)
plt.show()
Total running time of the script: (0 minutes 2.612 seconds)
Estimated memory usage: 9 MB