apply_transformations#
- mobgap.utils.df_operations.apply_transformations(
- df: DataFrame,
- transformations: list[tuple[str, callable | list[callable]] | CustomOperation],
- *,
- missing_columns: Literal['raise', 'ignore', 'warn'] = 'warn',
Apply a set of transformations to DataFrame.
Compared to the default pandas
df.transformmethod, this allows more flexibility in selecting the data to apply the transformations to and in defining the transformations themselves. In particular, it allows to apply transformations that require multiple columns as input.- Parameters:
- df
The DataFrame containing the data to transform. This can have a single or multi-level column index. The identifiers provided for the transformations must be valid loc identifiers for the DataFrame.
- transformations
A list specifying which transformation functions are to the df. They can be provided in two ways:
As a tuple in the format
(<identifier>, <function>), where<identifier>is a valid loc columns-indexer for the DataFrame, and<function>is the function (or a list of functions) to apply. When the identfier returns a sub-dataframe with multiple columns, then the function will get this entire subdataframe to operate on. However, we always expect the function to just return a single Series with the same number of rows as the dataframe.As a named tuple of type
CustomOperationtaking three arguments:identifier,function, andcolumn_name.identifieris a valid loc identifier selecting one or more columns from the dataframe,functionis the (custom) transformation function or list of functions to apply, andcolumn_nameis the name of the resulting column in the output dataframe.column_nameprovides the name of the resulting column in the output dataframe. This should either be a string or a tuple of strings, matching the “depth” of the<identifier>used in the normal transformations (if a combination is provided). This allows for more complex transformations that require multiple columns as input. We also support a special case, where the custom function returns a tuple of results (e.g. two Series). In this case, thecolumn_nameshould be a list of strings or tuples of strings, where each string corresponds to one of the results returned by the function. Note, that your custom function MUST return a tuple in this case (not a list or other iterable).
- missing_columns
How to handle missing columns specified in the transformations.
“raise”: Raise a
MissingDataColumnsError.“ignore”: Ignore the missing columns and continue with the remaining transformations.
“warn”: Issue a warning and continue with the remaining transformations (default).
- Returns:
- transformed_df
Dataframe with the transformed values. The columns of the transformed DataFrame are multi-level and will have the form
(*idetifier, function_name)
Notes
Warning
When mixing custom operations with built-in aggregations, make sure that the number of levels in the identifiers of the normal aggregations and the number of levels in the
column_nameattribute of the custom aggregations are identical. Otherwise, they can not be combined.
Examples using mobgap.utils.df_operations.apply_transformations#



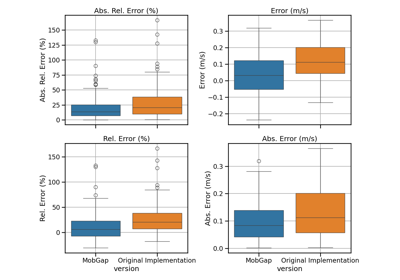
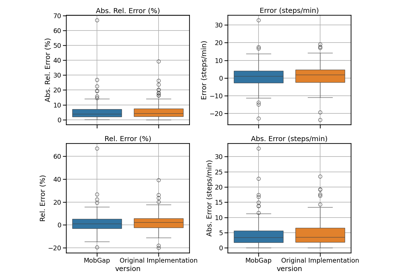
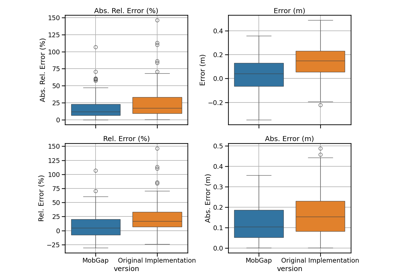
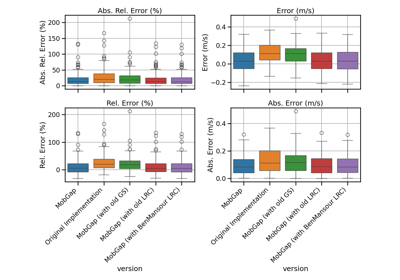
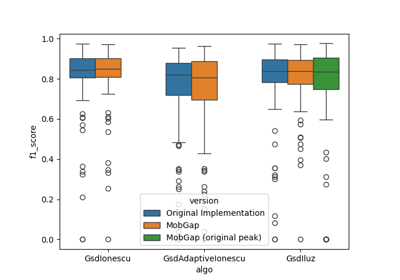
Performance of the gait sequences algorithm on the TVS dataset
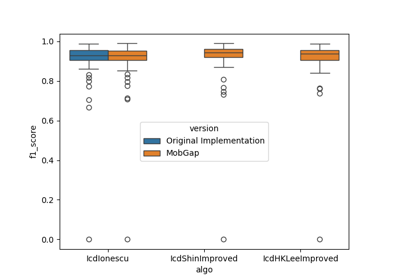
Performance of the initial contact algorithms on the TVS dataset
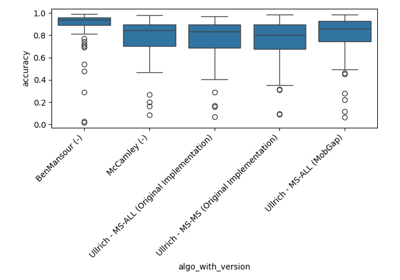
Performance of the laterality classification algorithms on the TVS dataset
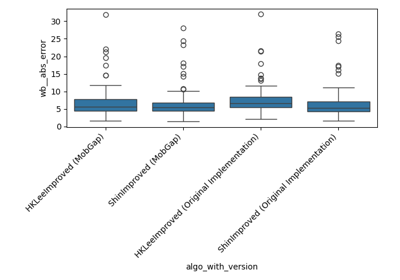
Performance of the cadence algorithms on the TVS dataset
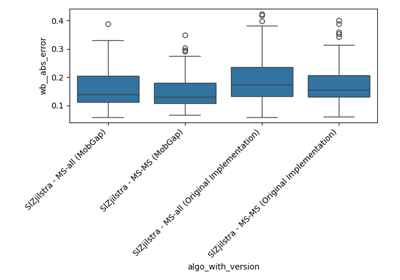
Performance of the stride length algorithms on the TVS dataset
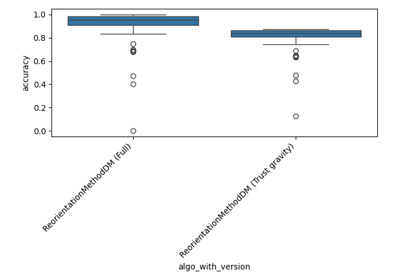
Performance of the reorientation algorithm on simulated TVS misorientations