Note
Go to the end to download the full example code.
Performance of the cadence algorithms on the TVS dataset#
The following provides an analysis and comparison of the cadence algorithms on the TVS dataset (lab and free-living). We look into the actual performance of the algorithms compared to the reference data. Note, that at the time of writing, comparison with the original Matlab results is not possible, as these algorithms were not run on the same version of the TVS dataset.
Note
If you are interested in how these results are calculated, head over to the processing page.
Below are the list of algorithms that we will compare. Note, that we use the prefix “MobGap” to refer to the reimplemented python algorithms.
algorithms = {
"HKLeeImproved": ("HKLeeImproved", "MobGap"),
"ShinImproved": ("ShinImproved", "MobGap"),
"matlab_HKLee_Imp2": ("HKLeeImproved", "Original Implementation"),
"matlab_Shin_Imp": ("ShinImproved", "Original Implementation"),
}
The code below loads the data and prepares it for the analysis.
By default, the data will be downloaded from an online repository (and cached locally).
If you want to use a local copy of the data, you can set the MOBGAP_VALIDATION_DATA_PATH environment variable.
and the MOBGAP_VALIDATION_USE_LOCA_DATA to 1.
The file download will print a couple log information, which can usually be ignored.
You can also change the version parameter to load a different version of the data.
from pathlib import Path
import pandas as pd
from mobgap.data.validation_results import ValidationResultLoader
from mobgap.utils.misc import get_env_var
def format_loaded_results(
values: dict[tuple[str, str], pd.DataFrame],
index_cols: list[str],
convert_rel_error: bool = False,
) -> pd.DataFrame:
formatted = (
pd.concat(values, names=["algo", "version", *index_cols])
.reset_index()
.assign(
algo_with_version=lambda df: (
df["algo"] + " (" + df["version"] + ")"
),
_combined="combined",
)
)
if not convert_rel_error:
return formatted
rel_cols = [c for c in formatted.columns if "rel_error" in c]
formatted[rel_cols] = formatted[rel_cols] * 100
return formatted
local_data_path = (
Path(get_env_var("MOBGAP_VALIDATION_DATA_PATH")) / "results"
if int(get_env_var("MOBGAP_VALIDATION_USE_LOCAL_DATA", 0))
else None
)
__RESULT_VERSION = "v1.0.0"
__RESULT_VERSION = "v1.0.0"
loader = ValidationResultLoader(
"cad", result_path=local_data_path, version=__RESULT_VERSION
)
free_living_index_cols = [
"cohort",
"participant_id",
"time_measure",
"recording",
"recording_name",
"recording_name_pretty",
]
free_living_results = format_loaded_results(
{
v: loader.load_single_results(k, "free_living")
for k, v in algorithms.items()
},
free_living_index_cols,
convert_rel_error=True,
)
lab_index_cols = [
"cohort",
"participant_id",
"time_measure",
"test",
"trial",
"test_name",
"test_name_pretty",
]
lab_results = format_loaded_results(
{
v: loader.load_single_results(k, "laboratory")
for k, v in algorithms.items()
},
lab_index_cols,
convert_rel_error=True,
)
cohort_order = ["HA", "CHF", "COPD", "MS", "PD", "PFF"]
0%| | 0.00/12.5k [00:00<?, ?B/s]
0%| | 0.00/12.5k [00:00<?, ?B/s]
100%|█████████████████████████████████████| 12.5k/12.5k [00:00<00:00, 71.2MB/s]
0%| | 0.00/12.5k [00:00<?, ?B/s]
0%| | 0.00/12.5k [00:00<?, ?B/s]
100%|█████████████████████████████████████| 12.5k/12.5k [00:00<00:00, 84.7MB/s]
0%| | 0.00/12.4k [00:00<?, ?B/s]
0%| | 0.00/12.4k [00:00<?, ?B/s]
100%|█████████████████████████████████████| 12.4k/12.4k [00:00<00:00, 83.0MB/s]
0%| | 0.00/12.5k [00:00<?, ?B/s]
0%| | 0.00/12.5k [00:00<?, ?B/s]
100%|█████████████████████████████████████| 12.5k/12.5k [00:00<00:00, 87.1MB/s]
0%| | 0.00/97.2k [00:00<?, ?B/s]
0%| | 0.00/97.2k [00:00<?, ?B/s]
100%|██████████████████████████████████████| 97.2k/97.2k [00:00<00:00, 605MB/s]
0%| | 0.00/96.4k [00:00<?, ?B/s]
0%| | 0.00/96.4k [00:00<?, ?B/s]
100%|██████████████████████████████████████| 96.4k/96.4k [00:00<00:00, 622MB/s]
0%| | 0.00/92.4k [00:00<?, ?B/s]
0%| | 0.00/92.4k [00:00<?, ?B/s]
100%|██████████████████████████████████████| 92.4k/92.4k [00:00<00:00, 597MB/s]
0%| | 0.00/94.6k [00:00<?, ?B/s]
0%| | 0.00/94.6k [00:00<?, ?B/s]
100%|██████████████████████████████████████| 94.6k/94.6k [00:00<00:00, 607MB/s]
Performance metrics#
Below you can find the setup for all performance metrics that we will calculate.
We only use the wb__ results for the comparison.
These results are calculated by first calculating the average cadence per WB.
Then calculating the error metrics for each WB.
Then we take the average over all WBs of a participant to get the wb__ results.
from functools import partial
from mobgap.pipeline.evaluation import CustomErrorAggregations as A
from mobgap.utils.df_operations import (
CustomOperation,
apply_aggregations,
apply_transformations,
multilevel_groupby_apply_merge,
)
from mobgap.utils.tables import FormatTransformer as F
from mobgap.utils.tables import RevalidationInfo, revalidation_table_styles
from mobgap.utils.tables import StatsFunctions as S
custom_aggs = [
CustomOperation(
identifier=None,
function=A.n_datapoints,
column_name=[("n_datapoints", "all")],
),
CustomOperation(
identifier=None,
function=lambda df_: df_["wb__detected"].isna().sum(),
column_name=[("n_nan_detected", "all")],
),
("wb__detected", ["mean", A.conf_intervals]),
("wb__reference", ["mean", A.conf_intervals]),
("wb__error", ["mean", A.loa]),
("wb__abs_error", ["mean", A.conf_intervals]),
("wb__rel_error", ["mean", A.conf_intervals]),
("wb__abs_rel_error", ["mean", A.conf_intervals]),
CustomOperation(
identifier=None,
function=partial(
A.icc,
reference_col_name="wb__reference",
detected_col_name="wb__detected",
icc_type="icc2",
# For the lab data, some trials have no results for the Original algorithms.
nan_policy="omit",
),
column_name=[("icc", "wb_level"), ("icc_ci", "wb_level")],
),
]
stats_transform = [
CustomOperation(
identifier=None,
function=partial(
S.pairwise_tests,
value_col=c,
between="version",
reference_group_key="Original Implementation",
),
column_name=[("stats_metadata", c)],
)
for c in [
"wb__abs_error",
"wb__abs_rel_error",
]
]
format_transforms = [
CustomOperation(
identifier=None,
function=lambda df_: df_[("n_datapoints", "all")].astype(int),
column_name="n_datapoints",
),
CustomOperation(
identifier=None,
function=lambda df_: df_[("n_nan_detected", "all")].astype(int),
column_name="n_nan_detected",
),
*(
CustomOperation(
identifier=None,
function=partial(
F.value_with_metadata,
value_col=("mean", c),
other_columns={
"range": ("conf_intervals", c),
"stats_metadata": ("stats_metadata", c),
},
),
column_name=c,
)
for c in [
"wb__reference",
"wb__detected",
"wb__abs_error",
"wb__rel_error",
"wb__abs_rel_error",
]
),
CustomOperation(
identifier=None,
function=partial(
F.value_with_metadata,
value_col=("mean", "wb__error"),
other_columns={"range": ("loa", "wb__error")},
),
column_name="wb__error",
),
CustomOperation(
identifier=None,
function=partial(
F.value_with_metadata,
value_col=("icc", "wb_level"),
other_columns={"range": ("icc_ci", "wb_level")},
),
column_name="icc",
),
]
final_names = {
"n_datapoints": "# participants",
"wb__detected": "WD mean and CI [steps/min]",
"wb__reference": "INDIP mean and CI [steps/min]",
"wb__error": "Bias and LoA [steps/min]",
"wb__abs_error": "Abs. Error [steps/min]",
"wb__rel_error": "Rel. Error [%]",
"wb__abs_rel_error": "Abs. Rel. Error [%]",
"icc": "ICC",
"n_nan_detected": "# Failed WBs",
}
validation_thresholds = {
"Abs. Error [steps/min]": RevalidationInfo(
threshold=None, higher_is_better=False
),
"Abs. Rel. Error [%]": RevalidationInfo(
threshold=20, higher_is_better=False
),
"ICC": RevalidationInfo(threshold=0.7, higher_is_better=True),
"# Failed WBs": RevalidationInfo(threshold=None, higher_is_better=False),
}
def format_tables(df: pd.DataFrame) -> pd.DataFrame:
return (
df.pipe(apply_transformations, format_transforms)
.rename(columns=final_names)
.loc[:, list(final_names.values())]
)
Free-Living Comparison#
We focus on the free-living data for the comparison as this is the expected use case for the algorithms.
All results across all cohorts#
The results below represent the average performance across all participants independent of the cohort.
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots()
sns.boxplot(
data=free_living_results, x="algo_with_version", y="wb__abs_error", ax=ax
)
plt.xticks(rotation=45, ha="right")
fig.tight_layout()
fig.show()
perf_metrics_all = free_living_results.pipe(
multilevel_groupby_apply_merge,
[
(
["algo", "version"],
partial(apply_aggregations, aggregations=custom_aggs),
),
(
["algo"],
partial(apply_transformations, transformations=stats_transform),
),
],
).pipe(format_tables)
perf_metrics_all.style.pipe(
revalidation_table_styles,
validation_thresholds,
["algo"],
)
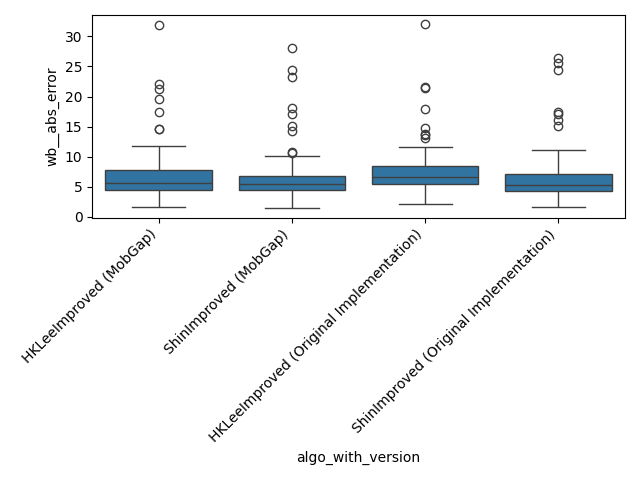
Per Cohort#
The results below represent the average performance across all participants within a cohort.
fig, ax = plt.subplots()
sns.boxplot(
data=free_living_results,
x="cohort",
y="wb__abs_error",
hue="algo_with_version",
order=cohort_order,
ax=ax,
)
fig.show()
perf_metrics_cohort = (
free_living_results.pipe(
multilevel_groupby_apply_merge,
[
(
["cohort", "algo", "version"],
partial(apply_aggregations, aggregations=custom_aggs),
),
(
["cohort", "algo"],
partial(apply_transformations, transformations=stats_transform),
),
],
)
.pipe(format_tables)
.loc[cohort_order]
)
perf_metrics_cohort.style.pipe(
revalidation_table_styles,
validation_thresholds,
["cohort", "algo"],
)
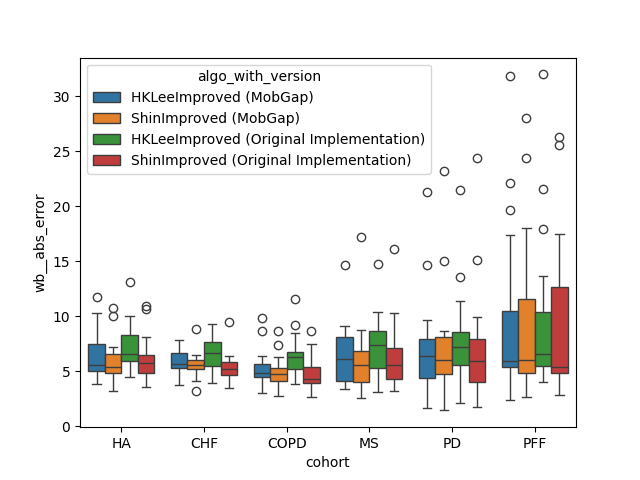
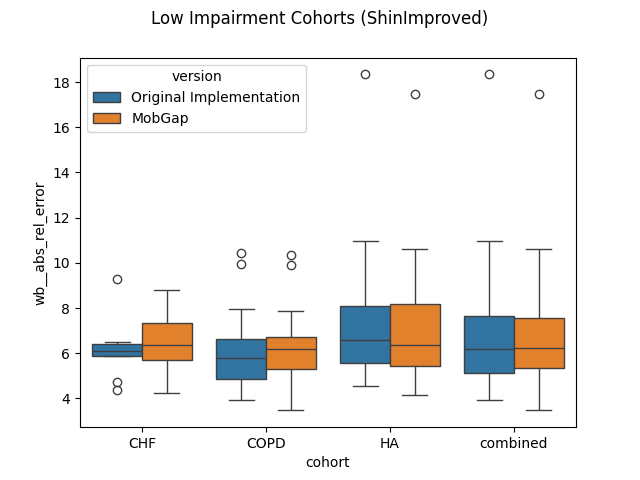
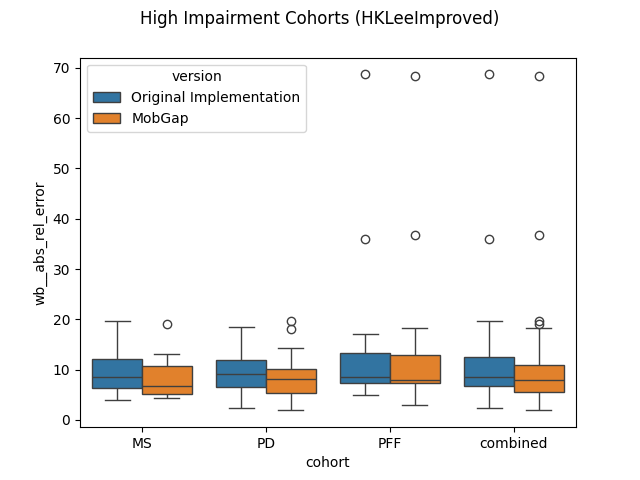
Per relevant cohort#
Overview over all cohorts is good, but this is not how the Cadence algorithms are used in our main pipeline.
Here, the HA, CHF, and COPD cohort use the IcdShinImproved algorithm, while the IcdHKLeeImproved
algorithm is used for the MS, PD, PFF cohorts.
Let’s look at the performance of these algorithms on the respective cohorts.
from mobgap.pipeline import MobilisedPipelineHealthy, MobilisedPipelineImpaired
low_impairment_algo = "ShinImproved"
low_impairment_cohorts = list(MobilisedPipelineHealthy().recommended_cohorts)
low_impairment_results = free_living_results[
free_living_results["cohort"].isin(low_impairment_cohorts)
].query("algo == @low_impairment_algo")
hue_order = ["Original Implementation", "MobGap"]
fig, ax = plt.subplots()
sns.boxplot(
data=low_impairment_results,
x="cohort",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
ax=ax,
)
sns.boxplot(
data=low_impairment_results,
x="_combined",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
legend=False,
ax=ax,
)
fig.suptitle(f"Low Impairment Cohorts ({low_impairment_algo})")
fig.show()
perf_metrics_cohort.copy().loc[
pd.IndexSlice[low_impairment_cohorts, low_impairment_algo], :
].reset_index("algo", drop=True).style.pipe(
revalidation_table_styles,
validation_thresholds,
["cohort"],
)
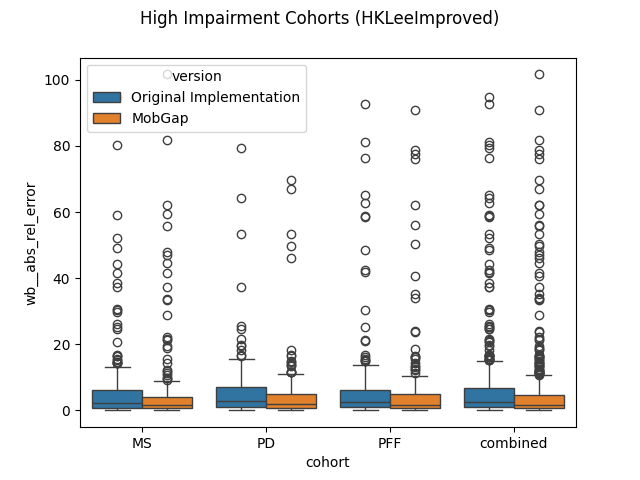
high_impairment_algo = "HKLeeImproved"
high_impairment_cohorts = list(MobilisedPipelineImpaired().recommended_cohorts)
high_impairment_results = free_living_results[
free_living_results["cohort"].isin(high_impairment_cohorts)
].query("algo == @high_impairment_algo")
fig, ax = plt.subplots()
sns.boxplot(
data=high_impairment_results,
x="cohort",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
ax=ax,
)
sns.boxplot(
data=high_impairment_results,
x="_combined",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
legend=False,
ax=ax,
)
fig.suptitle(f"High Impairment Cohorts ({high_impairment_algo})")
fig.show()
perf_metrics_cohort.copy().loc[
pd.IndexSlice[high_impairment_cohorts, high_impairment_algo], :
].reset_index("algo", drop=True).style.pipe(
revalidation_table_styles,
validation_thresholds,
["cohort"],
)
Speed dependency#
One important aspect of the algorithm performance is the dependency on the walking speed. Aka, how well do the algorithms perform at different walking speeds. For this we plot the absolute relative error against the walking speed of the reference data. For better granularity, we use the values per WB, instead of the aggregates per participant.
The overlayed dots represent the trend-line calculated by taking the median of the absolute relative error within bins of 0.05 m/s.
import numpy as np
wb_level_results = format_loaded_results(
{
v: loader.load_single_csv_file(
k, "free_living", "raw_wb_level_values_with_errors.csv"
)
for k, v in algorithms.items()
},
free_living_index_cols,
)
algo_names = wb_level_results.algo_with_version.unique()
fig, axs = plt.subplots(
len(algo_names),
1,
sharex=True,
sharey=True,
figsize=(12, 3 * len(algo_names)),
)
for ax, algo in zip(axs, algo_names):
data = wb_level_results.query("algo_with_version == @algo").copy()
# Create scatter plot
sns.scatterplot(
data=data,
x="reference_ws",
y="abs_rel_error",
ax=ax,
alpha=0.3,
)
# Create bins and calculate medians
bins = np.arange(0, data["reference_ws"].max() + 0.05, 0.05)
data["speed_bin"] = pd.cut(data["reference_ws"], bins=bins)
# Calculate bin centers for plotting
data["bin_center"] = data["speed_bin"].apply(lambda x: x.mid)
# Calculate medians per bin and cohort
binned_data = (
data.groupby("bin_center", observed=True)["abs_rel_error"]
.median()
.reset_index()
)
# Plot median lines
sns.scatterplot(
data=binned_data,
x="bin_center",
y="abs_rel_error",
ax=ax,
)
ax.set_title(algo)
ax.set_xlabel("Walking Speed (m/s)")
ax.set_ylabel("Absolute Relative Error")
fig.tight_layout()
fig.show()
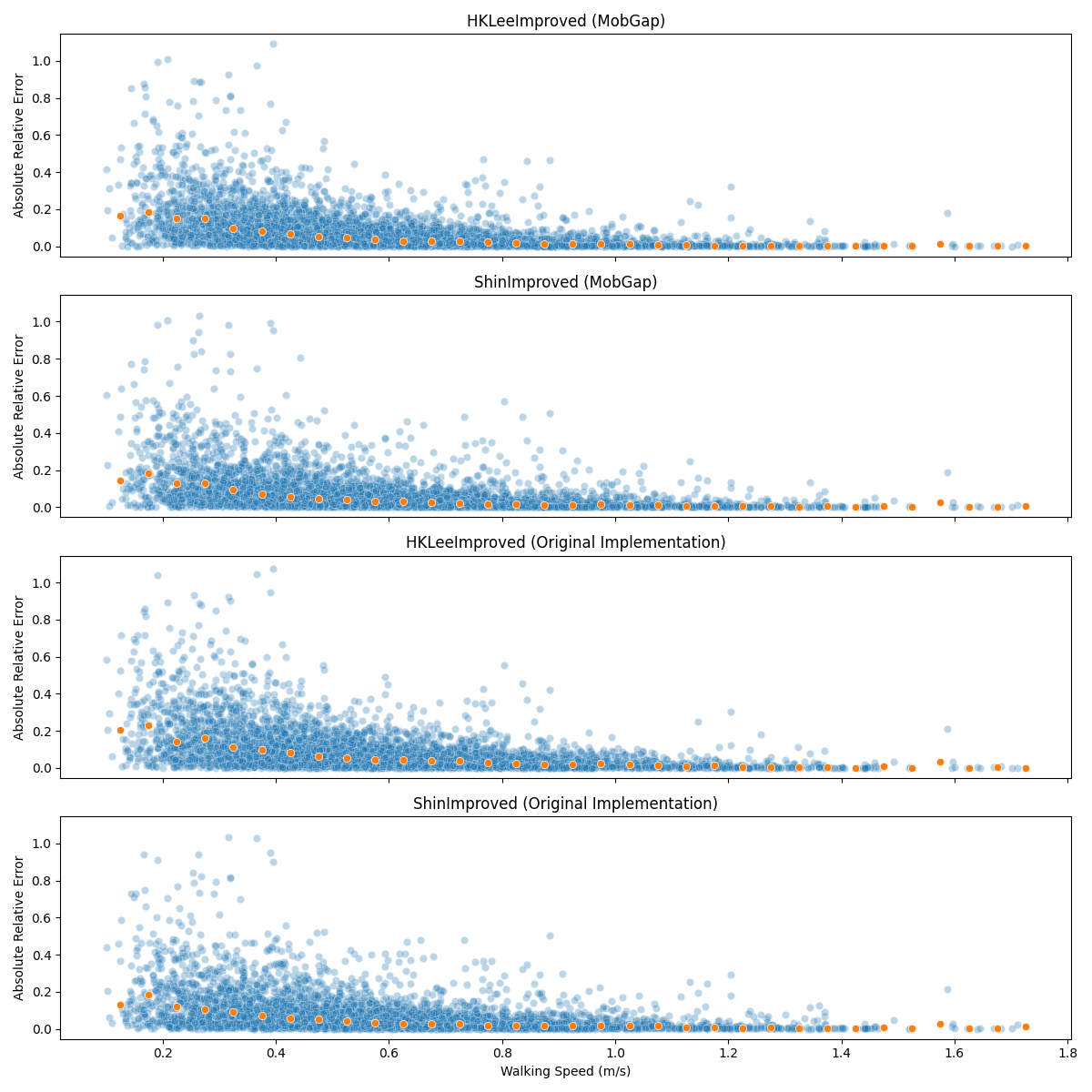
0%| | 0.00/289k [00:00<?, ?B/s]
0%| | 0.00/289k [00:00<?, ?B/s]
100%|███████████████████████████████████████| 289k/289k [00:00<00:00, 1.36GB/s]
0%| | 0.00/287k [00:00<?, ?B/s]
0%| | 0.00/287k [00:00<?, ?B/s]
100%|███████████████████████████████████████| 287k/287k [00:00<00:00, 1.57GB/s]
0%| | 0.00/288k [00:00<?, ?B/s]
0%| | 0.00/288k [00:00<?, ?B/s]
100%|███████████████████████████████████████| 288k/288k [00:00<00:00, 1.58GB/s]
0%| | 0.00/290k [00:00<?, ?B/s]
0%| | 0.00/290k [00:00<?, ?B/s]
100%|███████████████████████████████████████| 290k/290k [00:00<00:00, 1.49GB/s]
Laboratory Comparison#
Every datapoint below is one trial of a test. Note, that each datapoint is weighted equally in the calculation of the performance metrics. This is a limitation of this simple approach, as the number of strides per trial and the complexity of the context can vary significantly. For a full picture, different groups of tests should be analyzed separately. The approach below should still provide a good overview to compare the algorithms.
All results across all cohorts#
The results below represent the average performance across all participants independent of the cohort.
fig, ax = plt.subplots()
sns.boxplot(data=lab_results, x="algo_with_version", y="wb__abs_error", ax=ax)
plt.xticks(rotation=45, ha="right")
fig.tight_layout()
fig.show()
perf_metrics_all = lab_results.pipe(
multilevel_groupby_apply_merge,
[
(
["algo", "version"],
partial(apply_aggregations, aggregations=custom_aggs),
),
(
["algo"],
partial(apply_transformations, transformations=stats_transform),
),
],
).pipe(format_tables)
perf_metrics_all.style.pipe(
revalidation_table_styles,
validation_thresholds,
["algo"],
)
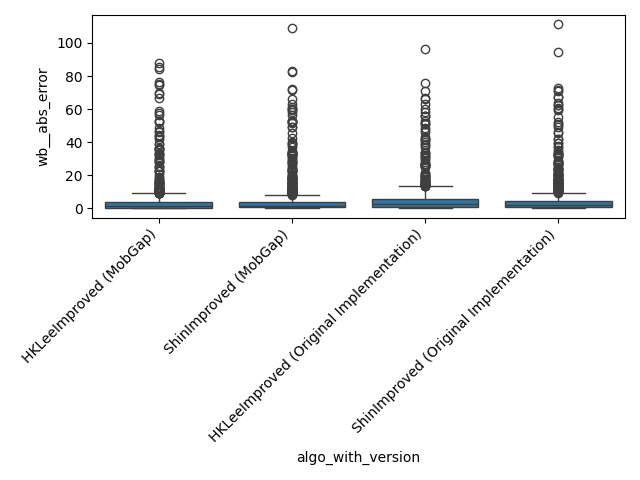
Per Cohort#
The results below represent the average performance across all trails of all participants within a cohort.
fig, ax = plt.subplots()
sns.boxplot(
data=lab_results,
x="cohort",
y="wb__abs_error",
hue="algo_with_version",
order=cohort_order,
ax=ax,
)
fig.show()
perf_metrics_cohort = (
lab_results.pipe(
multilevel_groupby_apply_merge,
[
(
["cohort", "algo", "version"],
partial(apply_aggregations, aggregations=custom_aggs),
),
(
["cohort", "algo"],
partial(apply_transformations, transformations=stats_transform),
),
],
)
.pipe(format_tables)
.loc[cohort_order]
)
perf_metrics_cohort.style.pipe(
revalidation_table_styles,
validation_thresholds,
["cohort", "algo"],
)
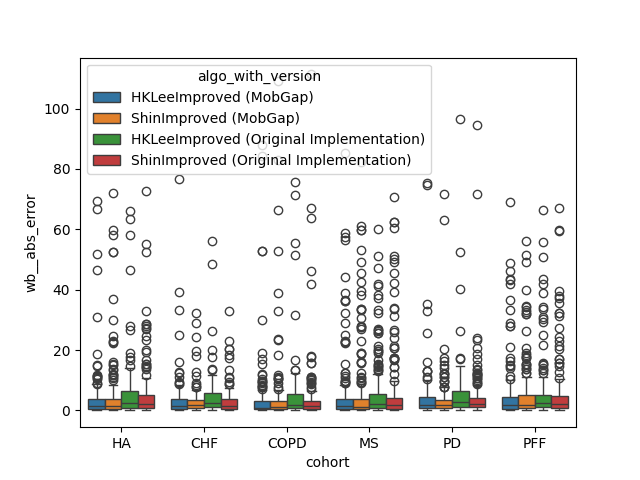
Per relevant cohort#
Overview over all cohorts is good, but this is not how the Cadence algorithms are used in our main pipeline.
Here, the HA, CHF, and COPD cohort use the IcdShinImproved algorithm, while the IcdHKLeeImproved
algorithm is used for the MS, PD, PFF cohorts.
Let’s look at the performance of these algorithms on the respective cohorts.
low_impairment_results = lab_results[
lab_results["cohort"].isin(low_impairment_cohorts)
].query("algo == @low_impairment_algo")
hue_order = ["Original Implementation", "MobGap"]
fig, ax = plt.subplots()
sns.boxplot(
data=low_impairment_results,
x="cohort",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
ax=ax,
)
sns.boxplot(
data=low_impairment_results,
x="_combined",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
legend=False,
ax=ax,
)
fig.suptitle(f"Low Impairment Cohorts ({low_impairment_algo})")
fig.show()
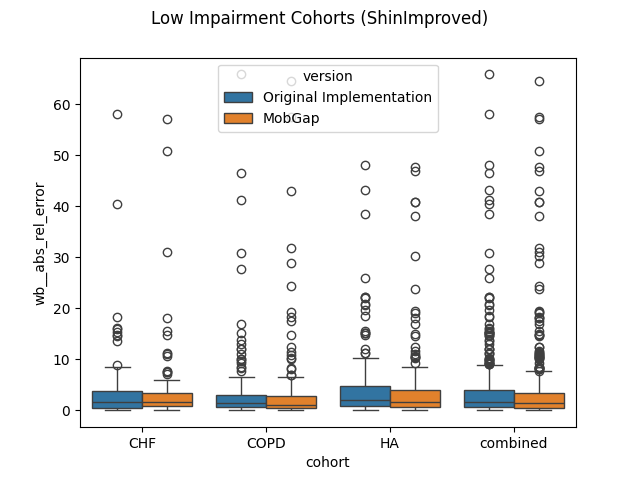
perf_metrics_cohort.copy().loc[
pd.IndexSlice[low_impairment_cohorts, low_impairment_algo], :
].reset_index("algo", drop=True).style.pipe(
revalidation_table_styles,
validation_thresholds,
["cohort"],
)
high_impairment_results = lab_results[
lab_results["cohort"].isin(high_impairment_cohorts)
].query("algo == @high_impairment_algo")
fig, ax = plt.subplots()
sns.boxplot(
data=high_impairment_results,
x="cohort",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
ax=ax,
)
sns.boxplot(
data=high_impairment_results,
x="_combined",
y="wb__abs_rel_error",
hue="version",
hue_order=hue_order,
legend=False,
ax=ax,
)
fig.suptitle(f"High Impairment Cohorts ({high_impairment_algo})")
fig.show()
perf_metrics_cohort.copy().loc[
pd.IndexSlice[high_impairment_cohorts, high_impairment_algo], :
].reset_index("algo", drop=True).style.pipe(
revalidation_table_styles,
validation_thresholds,
["cohort"],
)
Total running time of the script: (0 minutes 11.850 seconds)
Estimated memory usage: 80 MB